Description
Hey, so I created this Discourse Forum Scrapper and made a Network Analysis BoilerPlate jupyter notebook
pulled into main Github with https://github.com/DiamondDAO/dao-research/pull/2
For the fun of it, here’s the current DiamondDAO User network:
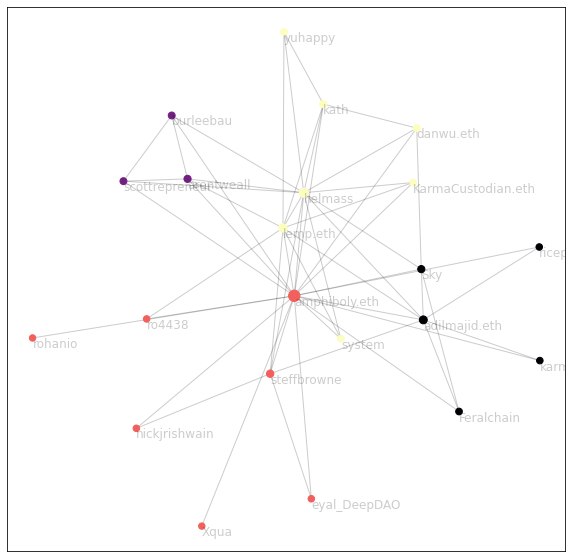
Here is the description for others to review:
Discourse scrapper
This script will utilize the Discourse API to gather all the data about user behavior from a discourse forum.
Requirements
- requests
- json
- tqdm
- os
- argparse
- time
Install requierements by using pip with pip install -r requierements.txt
Usage
usage: DiscourseScrapper.py [-h] -b base_url -o out_path [-s category_slug] [-i category_id]
Discourse Forum Parser.
optional arguments:
-h, --help show this help message and exit
-b base_url, --url base_url
The base url for the Discourse forum to scrape data from, starting with http:// or https://
-o out_path, --out out_path
The location for the folder containing the result of the scrapping.
-s category_slug, --slug category_slug
IF restricting to one category only, the slug of that category. (requries -i to be set as well)
-i category_id, --id category_id
IF restricting to one category only, the id of that category. (requries -s to be set as well)
Example usage of the resulting data
This can be foudn in the DiscourseNetwork.ipynb file in the same repository.
API information
All information was found from the main page of the API documentation except for the number of likes which is located here On the forums